此文转自@dodola 原文地址:https://www.zybuluo.com/dodola/note/554061
前言
从微信公众号介绍 Tinker 开始就一直关注 Tinker,自己也一直在做热修复相关的开发,但一直都是在踩坑的状态,在 MDCC 的时候也和邵文同学聊了一下,从看到框架代码开始就觉得其稳定性相当的好,而整个框架里我在意的几部分是:
1. DexDiff
我觉得这是最体现微信做事风格的一个模块:要把一个技术做到极致,像之前开源的几种方案里 Andfix 的补丁粒度是方法,像 nuwa、rocoofix 类似的补丁粒度是类,其他有很多采用 bsdiff 的,其实上述的方法都会由于一些的情况造成补丁包变得很大(这个后面会讲原因),而 Tinker 是基于 Dex 的文件结构来下手,将产生变化的结构提取出来,产生的补丁非常小,而且在 diff 的过程中也处理了一些会造成补丁包很大的场景,这个后续再谈。之前有同学跟我说这个是反编译过程,其实并不是如此。
2. 资源 Diff
这块技术大家在做的时候大部分出现的问题都不在如何加载补丁资源包里,因为这块内容 InstantRun 里已经有很完整的解决方案,我们都在讨论同一个问题就是如何保证后续打包的资源 id 不变的问题,并且使用比较优雅的方式来集成进去,Tinker 里已经解决这个问题。
3. 分平台合成
DexDiff 生成了一个自定义格式的 dex,这个 dex 在不同的虚拟机环境下会区分 dalvik 和 art 平台合成不同的补丁包,而这种方式也是分别为了解决 dalvik 下和 art 下出现的问题产生的方案。这样就避免了 Dalvik 下需要宿主提前插桩才能解决验证问题等。
4. 补丁包的加载
这块遇到的问题其实有很多,比如如何判断 dex 、资源文件已经加载完成,如何判断这个机型不支持 ClassLoader 的 dex 插入机制,以及如何连续下发补丁,补丁的回退机制等等,Tinker 都已解决上述问题,并且提供了很完整的日志供开发同学分析。
5. MiniLoader
这个名词是从 Tinker 第一篇文章中看到的,像之前的框架基本上补丁的加载都是在 Application 的 onCreate里或者 attachBaseContext 里,这就会造成一个问题就是 Application 出现问题是无法被修复的, Tinker 为了解决这个问题采用了隔离 Application 的方式, Application 的初始化和声明周期由 MiniLoader 来进行代理这样我们就可以把很多操作放在代理类里完成, Application 和其提前加载的类都是可以进行修复的。
DexDiff
其实这个标题并不是很符合我下面要介绍的内容,我下面主要介绍一下在 Diff 过程中处理 Code Section 的内容,其他 Section 的 Diff 其实相对容易理解一些,大家看源码和这篇文章基本就明白了
从Dex说起
要了解整个 Diff 过程需要先熟悉一下Dex的文件结构,这里要老生常谈的描述一下 Dex 的 Section 结构和各个 Section 之间的关联性,我们以一段简单的代码为例。
% echo 'class Foo {'\> 'public static void main(String[] args) {'\> 'System.out.println("Hello, world"); }}' > Foo.java% javac Foo.java% dx --dex --output=foo.dex Foo.class
上述的命令将一段很简单的Hello World代码先经过 javac 编译成 .class文件,然后通过 dx命令 将 .class 文件转换成 Dex 也就是上面生成的一个foo.dex文件,这个文件就是我们下面要分析的文件.
我们先大体来看一下整个Dex的结构,从 AloneMonkey 的博客中找到一个描述DexFile整体结构的图
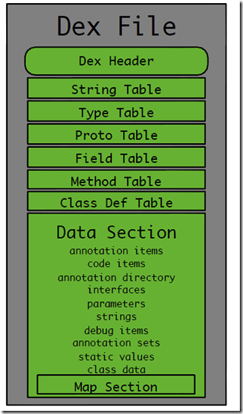
Tinker针对上面的Data Section部分每一项内容都做了相应的diff逻辑
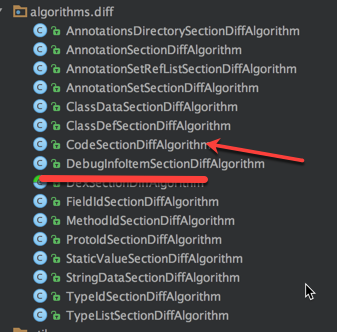
本次要讲的是CodeSectionDiffAlgorithm算法过程,由于新旧源码的变更和编译过程中的优化会导致字节码的一些改变从而引发 Diff 和 Merge 的过程中出现一些问题,我们会逐步介绍这些问题,并说明 Tinker 中是如何处理的。
所以我们先来了解一下Code Section里包含什么内容。
Code Section
我们在上一节中生成了一个只有一个静态main方法的dex类,这个类足够简单很适合用来分析。
其实通过分析class_data结构中可以看到其中其direct_methods_size是2,说明里面有两个方法,一个是编译器生成的构造方法Foo.<init>一个是我们定义的静态方法 public static void Foo.main(java.lang.String[])
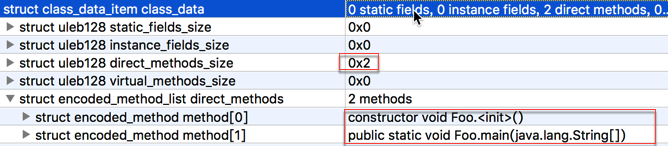
下面的图指出了在method结构里通过code_off字段引用到指定的code_item段,这个就是我们要分析的部分。
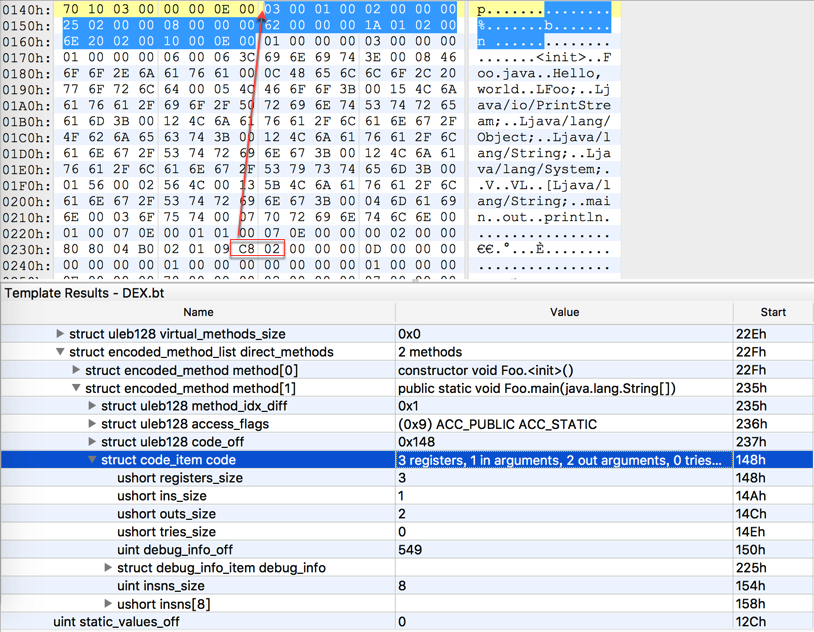
上面图中指出的code_item段的内容在Tinker里面通过com.tencent.tinker.android.dex.Code类对应
public final class Code extends Item<Code> {public int registersSize;//本段代码使用到的寄存器数目public int insSize;//method传入参数的数目public int outsSize;//本段代码调用其它method 时需要的参数个数public int debugInfoOffset;//指向调试信息的偏移public short[] instructions;//表示具体的字节码public Try[] tries;//try_item 数组public CatchHandler[] catchHandlers;}
然后Tinker在做diff的时候通过compareTo方法来判断方法里的代码是否经过修改。
@Overridepublic int compareTo(Code other) {int res = CompareUtils.sCompare(registersSize, other.registersSize);if (res != 0) {return res;}res = CompareUtils.sCompare(insSize, other.insSize);if (res != 0) {return res;}res = CompareUtils.sCompare(outsSize, other.outsSize);if (res != 0) {return res;}res = CompareUtils.sCompare(debugInfoOffset, other.debugInfoOffset);if (res != 0) {return res;}res = CompareUtils.uArrCompare(instructions, other.instructions);if (res != 0) {return res;}res = CompareUtils.aArrCompare(tries, other.tries);if (res != 0) {return res;}return CompareUtils.aArrCompare(catchHandlers, other.catchHandlers);}
上面的代码属性里的任何一项出现不同那么就认为用户修改过这个方法体。
不过,这一切并没有这么顺利。。。
我们需要考虑一下这种情况,有如下两段代码
Foo.java 下面的代码相当于我们上一个版本的代码
-
public class Foo { public void foo(){System.out.println("hello dodola5");}}
这段代码相当于我们修改过后的代码,下面这段代码并没有修改任何方法,只是增加了4个字符串属性。
public class Foo {public String foo1 = "hello dodola";public String foo5 = "hello dodola1";public String foo2 = "hello dodola2";public String foo3 = "hello dodola3";public String foo4 = "hello dodola4";public void foo(){System.out.println("hello dodola5");}}
那么直观上我们认为其中定义的方法从生成的code段的内容应该是没有任何变化的,但事实并不如此,我们以foo方法为例,两段代码中各自对应的foo方法的字节码如下:
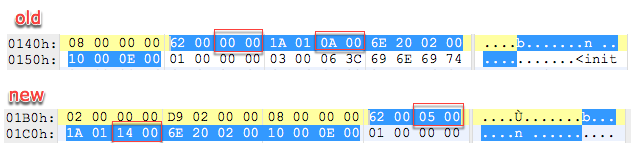
从上面的图上,我们可以看到,在这种情况下新旧版本里一个并没有修改过的方法生成的字节码并不一样。
让我们看看图中出现不一致的地方是什么内容,祭出dexdump来查看一下这部分生成的smali代码
旧版本
6200 0000 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@00001a01 0a00 |0002: const-string v1, "hello dodola5" // string@000a6e20 0200 1000 |0004: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00020e00 |0007: return-void
新版本
6200 0500 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@00051a01 1400 |0002: const-string v1, "hello dodola5" // string@00146e20 0200 1000 |0004: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00020e00 |0007: return-void
从上面两段代码的对比中我们可以看到虽然我们没有改变 hello dodola5 这个字符串的内容,但是这个字符串由于我们新增的字符串导致其string_id产生变化,也就是上述代码中出现的string@000a和string@0014的不同,并且由于字段的增加导致读取的field位置也是不同 sget-object指的是根据 字段ID 读取静态对象引用字段到 vx,这说明java.io.PrintStream java.lang.System.out 所在的fieldid变了。
所以,按照直接取出两个Code做对比的方法,在类似这种情况下虽然没有对其方法做修改,也是会被判定为different的,所以我们需要一个过程,将这样内容没有变化,id出现变化的情况,将新dex里的ID映射回旧dex的ID上面。这是_一方面_的考虑。
下面我们来具体讨论一下 Tinker 是如何做新旧 ID的映射的,这里使用 String ID 来做演示
public class Foo {public String foo1="hello dodola";public String foo5="hello dodola1";-
public String foo2="hello dodola2"; public void foo(){System.out.println("hello dodola5");}}
增加foo3,删除foo2,修改foo1,修改方法里字符串为hello dodola1,代码变成如下内容
public class Foo {public String foo1="hello dodola_modify";public String foo5="hello dodola1";-
public String foo3="hello dodola3"; public void foo(){System.out.println("hello dodola1");}}
好了,我们用上面修改的内容看一下 Tinker 里所用的diff算法的逻辑,下面以字符串的修改为例,先看一下两个dex里Strings部分的内容是什么样子的。
diff 算法
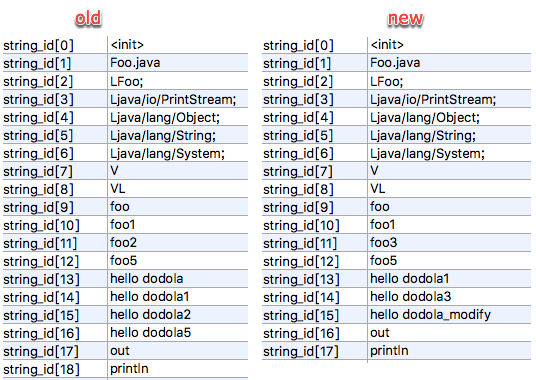
算法的过程比较简单,描述一下就是:首先我们需要将新旧内容排序,这需要针对排序的数组进行操作新旧两个指针,在内容一样的时候 old、new 指针同时加1,在 old 内容小于 new 内容(注:这里所说的内容比较是单纯的内容比较比如'A'<'a')的时候 old 指针加1 标记当前 old 项为删除在 old 内容大于 new 内容 new 指针加1, 标记当前 new 项为新增-
下面我列出了算法执行的简单过程 ------old-----11 foo212 foo513 hello dodola14 hello dodola115 hello dodola216 hello dodola517 out-
18 println ------new-----11 foo312 foo513 hello dodola114 hello dodola315 hello dodola_modify16 out-
17 println -
对比的old cursor 和 new cursor 指针的改变以及操作判定,判定过程如下 old_11 new_11 cmp <0 delold_12 new_11 cmp >0 addold_12 new_12 cmp =0 noold_13 new_13 cmp <0 delold_14 new_13 cmp =0 noold_15 new_14 cmp <0 delold_16 new_14 cmp >0 addold_16 new_15 cmp <0 delold_17 new_15 cmp >0 addold_17 new_16 cmp =0 no-
old_18 new_17 cmp =0 no break;-
进入下一步过程 -
可以确定的是删除的内容肯定是从 old 中的 index 进行删除的 添加的内容肯定是从 new 中的 index 中来的,按照这个逻辑我们可以整理如下内容。 old_11 delnew_11 addold_13 delnew_14 addold_15 delnew_15 add-
old_16 del -
到这一步我们需要找出替换的内容,很明显替换的内容就是从 old 中 del 的并且在 new 中 add 的并且 index 相同的i tem,所以这就简单了 old_11 replaceold_13 delnew_14 addold_15 replace-
old_16 del ok,到这一步我们就能判定出两个dex的变化了。很机智的算法
总觉得这算法略熟悉,但是叫不上名字,问过小唐同学后才知道这是二路归并算法,算法这部分还需要学习,惭愧。
上面的内容过于混杂,下面拆分出各个知识点进行介绍。
首先我们需要考虑的内容是如何找出像上面出现的那种方法没有修改但是其字节码产生变化的情况,所以我们需要彻底了解一遍Dalvik bytecode,这也有助于我们对后面的分析。
so next
bytecode 简要说明
指令说明
在阅读官网文档之前我们需要先了解一些东西,由于能力有限下面的内容大部分来自网上的文档。
Dalvik虚拟机是基于寄存器的,在java字节转换为dalvik字节码的过程中,方法调用栈的尺寸就已经确定,其中明确指出了方法使用寄存器的个数
这里先引用非虫《Android软件安全与逆向分析》书中对字节码的讲解。
一段Dalvik字节码由一系列Dalvik指令组成,指令语法由指令的位描述与指令格式标识来决定。位描述约定如下:
- 每16位的字采用空格分隔开来。
-
每个字母表示4位,每个字母按顺序从高字节开始,排列到低字节。每4位之间可能使有竖线“ ”来表示不同的内容。 - 顺序采用A~Z的单个大写字母作为一个4位的操作码,op表示一个8位的操作码。
- “Ø”来表示这字段所有位为0值。
以指令格式A|G|op BBBB F|E|D|C为例:
指令中间有两个空格,每个分开的部分大小为16位,所以这条指令由三个16位的字组成。第一个16位是A|G|op,高8位由A与G组成,低字节由操作码op组成。第二个16位由BBBB组成,它表示一个16位的偏移值。第三个16位分别由F,E,D,C共四个4位组成,在这里它们表示寄存器参数。
在实际存储时,是以小端方式,而在描述时,则以大端方式。
单独使用位标识还无法确定一条指令,必须通过指令格式标识来指定指令的格式编码。它的约定如下:
- 指令格式标识大多由三个字符组成,前两个是数字,最后一个是字母。
- 第一个数字是表示指令有多少个16位的字组成。
- 第二个数字是表示指令最多使用寄存器的个数。特殊标记“r”标识使用一定范围内的寄存器。
- 第三个字母为类型码,表示指令用到的额外数据的类型。取值见下表。
- 还有一种特殊的情况是末尾可能会多出另一个字母,如果是字母
s表示指令采用静态链接,如果是字母i表示指令应该被内联处理

以指令格式标识22x为例:
第一个数字2表示指令有两个16位字组成,第二个数字2表示指令使用到2个寄存器,第三个字母x表示没有使用到额外的数据。
另外,Dalvik指令对语法做了一些说明,它约定如下:
-
格式表的第三列指出了指令中所使用的人类可识别的语法。每个指令以命名的操作码开始,后面可选择使用一个或多个参数,并且参数之间用逗号分隔。
-
当参数指第一列中的某个字段时,该字段的字母将在语法中出现,并在字段中每四位重复一次。例如,第一列中标记为“BB”的八位字段在语法列中也将标记为“BB”。
-
命名寄存器的参数形式为“vX”。选择“v”而不是更常用的“r”作为前缀,这样可避免与实现 Dalvik 可执行格式的(非虚拟)架构(其寄存器使用“r”作为前缀)出现冲突。(也就是说,我们可以直截了当地同时讨论虚拟和实际寄存器。)
-
表示字面值的参数的形式为“#+X”。有些格式在表示字面量时,仅具有字面量的高位(无 0 位);对于这种类型的量,仅在语法表示时会明确写出后面的 0,但是在按位描述中这些 0 会被省略。
-
表明相对指令地址偏移量的参数形式为“+X”。
-
表示字面量常量池索引的参数形式为“kind@X”,其中“kind”表示正在引用的常量池。每个使用此类格式的操作码明确地表示只允许使用一种常量;请查看操作码参考,找出对应关系。常量池的种类包括“string”(字符串池索引)、“type”(类型池索引)、“field”(字段池索引)、“meth”(方法池索引)和“site”(调用点索引)。
-
此外还可使用一些建议的可选形式,它们与常量池索引的表示类似,表示预链接的偏移量或索引。可以使用两种类型的建议的预链接值:vtable 偏移(表示为“vtaboff”)和字段偏移(表示为“fieldoff”)。
-
如果格式值并非明确地包含在语法中,而是选择使用某种变体,则每个变体都以“[X=N]”(例如,“[A=2]”)为前缀来表示对应关系。
以指令 op vAA, string@BBBB 为例:指令用到了1个寄存器参数 vAA,并且还附加了一个字符串常量池索引 string@BBBB,其实这条指令格式代表着 const-string 指令。
在 Dalvik 虚拟机字节码中寄存器的命名法中主要有 2 种:
- v 命名法
- p 命名法。
假设一 个函数使用到 M 个寄存器,并且该函数有 N 个入参,根据 Dalvik 虚拟机参数传递方式中的规定:入参使用最后的 N 个寄存器中,局部变量使用从 v0 开始的前 M-N 个寄存器。比如, 某函数 A 使用了 5 个寄存器,2 个显式的整形参数,如果函数 A 是非静态方法,函数被调用 时会传入一个隐式的对象引用(也就是this),因此实际传入的参数个数是 3 个。根据传参规则,局部变量将使用前 2 个寄存器,参数会使用后 3 个寄存器。
v 命名法采用小写字母v开头的方式表示函数中用到的局部变量与参数,所有的寄存器命名从 v0 开始,依次递增。对于上文的函数 A,v 命名法会用到 v0、v1、v2、v3、v4 等 5 个寄存器,v0 与 v1 表示函数 A 的局部变量,v2 表示传入的隐式对象引用,v3 与 v4 表示实际传入的 2 个整形参数。
p 命名法对函数的局部变量寄存器命名没有影响,它的命名规则是:函数的入参从 p0 开始命名,依次递增。对于上文的函数 A,p 命名法会用到 v0、v1、p0、p1、p2 等 5 个寄 存器,v0 与 v1 表示函数 A 的局部变量,p0 表示传入的隐式对象引用,p1 与 p2 表示实际传 入的 2 个整形参数。此时,p0、p1、p2 实际上分别表示 v2、v3、v4,只是命名不一样而已。p命名法的好处是能够通过寄存器的名字前缀就能判断寄存器是局部变量还是函数入参。
这里需要注意个情况,在调用_非静态方法_的时候,需要传入该方法所在对象的引用也就是this,此时 p0 表示隐式对象引用,p1后面是实际传入的参数,在调用_静态方法_时,由于不需要对当前对象进行引用,所以从 p0 开始就是实际传入的参数,这点需要注意。
指令中使用v加数字的方法来索引寄存器,每条指令使用的寄存器索引范围都有限制,这里使用一个大写字母来表示4位数据宽度的取值范围,比如:指令 move vA, vB,目的寄存器 vA 可使用 v0 ~ v15 的寄存器,源寄存器 vB 可以使用 v0 ~ v15 寄存器。指令 move/from16 vAA, vBBBBB,目的寄存器 vAA 可使用 v0 ~ v255 的寄存器,源寄存器 vB 可以使用 v0 ~ v65535 寄 存器。当目的寄存器和源寄存器中有一个寄存器的编号大于 15 时,即需要加上 /from16 指令才能得到正确运行。
上面描述了一下dalvik bytecode中所使用的指令格式,所有格式的说明在https://source.android.com/devices/tech/dalvik/instruction-formats.html 这个官方文档中有说明,这里就不贴出了,在下面的内容中会涉及到。
Bytecode 指令
数据操作指令
01 12x
move vA,vB
A:目的寄存器(4bits) B:源寄存器(4bits)
将一个非对象寄存器的内容移到另一个非对象寄存器中。
12x: 指令长度16,两个寄存器
例子:01 10 : move v0, v1
02 22x
move/from16 vAA, vBBBB
A:目的寄存器(8its) B:源寄存器(16bits)
将一个非对象寄存器的内容移到另一个非对象寄存器中。
22x:指令长度32,两个寄存器
例子:02 01 1400 :move/from16 v1, v20
说明:出现from16的情况一般是一个方法里使用的寄存器超过15个
03 32x
move/16 vAAAA, vBBBB
A:目的寄存器(16its) B:源寄存器(16bits)
将一个非对象寄存器的内容移到另一个非对象寄存器中。
32x:指令长度48,两个寄存器
例子:
0300 0201 0000 : move/16 v258, v0
04 12x
move-wide vA, vB
A:目的寄存器(4bits) B:源寄存器(4bits)
将一个寄存器对的内容移到另一个寄存器对中。
12x:指令长度16,两个寄存器
例子:
public static long test3(long a,long b){return a+b;}
注意:可以从 vN 移到 vN-1 或 vN+1,因此必须在执行写入运算之前,为要读取的寄存器对的两部分均安排实现。
入参使用最后的几个寄存器,局部变量使用v0开始的前N个寄存器, 在此例中,registersize是12
v0
v1
v2
v3
v4
v5
v6
v7
v8
v9
v10
v11
0480 |0000: move-wide v0, v8 #04a2 |0001: move-wide v2, v10 #0404 |0002: move-wide v4, v0 #0426 |0003: move-wide v6, v2 #bb64 |0004: add-long/2addr v4, v6 #0440 |0005: move-wide v0, v4 #1000 |0006: return-wide v0 #
05 22x
move-wide/from16 vAA, vBBBB
A:目的寄存器(8bits) B:源寄存器(16bits)
将一个寄存器对的内容移到另一个寄存器对中。
22x:指令长度32,两个寄存器
例子:02 02 1600 :move/from16 v2, v22
该字节码会出现在寄存器使用超过15个的情况,并且操作数为long或者double
06 32x
move-wide/16 vAAAA, vBBBB
A:目的寄存器(16bits) B:源寄存器(16bits)
将一个寄存器对的内容移到另一个寄存器对中。
32x:指令长度48,两个寄存器
还未发现该字节码
07 12x
move-object vA, vB
A:目的寄存器(4bits) B:源寄存器(4bits)
将一个对象传送寄存器的内容移到另一个对象传送寄存器中
12x:指令长度16,两个寄存器
例子:07 30: move-object v0, v3 将v3寄存器中的对象引用到v0
08 22x
move-object/from16 vAA, vBBBB
A:目的寄存器(8bits) B:源寄存器(16bits)
将一个寄存器的对象内容移动到另一个寄存器
22x:指令长度32,两个寄存器
例子:0801 1200: move-object/from16 v1, v18 将v18寄存器中的对象引用到v1
09 32x
move-object/16 vAAAA, vBBBB
A:目的寄存器(16bits) B:源寄存器(16bits)
将一个寄存器的对象内容移动到另一个寄存器
32x:指令长度48,两个寄存器
0a 11x
move-result vAA
A:目的寄存器(8bits)
将最近invoke-kind调用的非对象单字节结果移动到指定的寄存器中, 这个操作必须立即在invoke-kind后调用,单字节非对象的结果不被忽略其他无效。
11x:指令长度16,一个寄存器
例子:0a01: move-result v1
此处需要注意的项是,这个结果是非对象型结果的,比如方法返回一个对象,那么紧接着的操作应该不会出现move-result,而应该是object系的操作。
0b 11x
move-result-wide vAA
A:目的寄存器(8bits)
移动最近由invoke-kind指令执行的双字节结果到一对寄存器中,必须在invoke-kind之后的指令后立即调用,除双字节结果外,其他类型结果被忽略
11x:指令长度16,一个寄存器
例子:
0013: invoke-interface {v5}, Zorch.zorch4:()J #此方法返回long0016: move-result-wide v5
0c 11x
move-result-object vAA
A:目的寄存器(8bits)
移动最近一次由invoke-kind产生的对象结果到指定的寄存器中,必须在invoke-kind或者filled-new-array后立即调用,对象结果外其他类型结果会被忽略
11x:指令长度16,一个寄存器
例子:
2420 0f00 2100 :filled-new-array {v1, v2}, [I // type@000f0c02 : move-result-object v2
0d 11x
move-exception vAA
A:目的寄存器(8bits)
将刚刚捕获的异常保存到给定寄存器中。该指令必须为捕获的异常不会被忽略的任何异常处理程序的第一条指令,且该指令必须仅作为异常处理程序的第一条指令执行,否则无效。
11x:指令长度16,一个寄存器
例子:
public static int tryCatch(String num){try{return Integer.parseInt(num);}catch(Exception ex){return 0;}-
} 0730 : move-object v0, v30702 : move-object v2, v07110 0500 0200 : invoke-static {v2}, Ljava/lang/Integer;.parseInt:(Ljava/lang/String;)I // method@00050a02 : move-result v20120 : move v0, v20f00 : return v00d02 : move-exception v20721 : move-object v1, v21202 : const/4 v2, #int 0 // #00120 : move v0, v228fb : goto 0007 // -0005
返回指令
0e 10x
return-void
从 void 方法返回。
10x:指令长度16,没有使用寄存器
例子:
0E00 : return-void #返回值为 void,即无返回值,并非返回 null。
0f 11x
return vAA
A:目的寄存器(8bits)
返回一个32位非对象类型的值,返回值寄存器为8位的寄存器vAA
11x:指令长度16,一个寄存器
例子:0F00 : return v0
10 11x
return-wide vAA
A:目的寄存器(8bits)
返回一个64位非对象类型的值,返回值为8位的寄存器对vAA
11x:指令长度16,一个寄存器
例子:
1000 : return-wide v0 #返回 v0,v1 寄存器中的 double/long 值。
11 11x
return-object vAA
A:目的寄存器(8bits)
返回一个对象类型的值。返回值为8位的寄存器vAA
11x:指令长度16,一个寄存器
例子:1100 : return-object v0 #返回v0寄存器中的对象引用
数据定义指令
12 11n
const/4 vA, #+B
A:目的寄存器(4bits) B:signed int(4位)
将数值符号扩展为32位后赋给寄存器vA
11n:指令长度16,一个寄存器,4位立即数
例子:
-
int b = 1; -
1212 : const/4 v2, #int 1 // #1
13 21s
const/16 vAA, #+BBBB
A:目的寄存器(8bits) B: signed int (16 bits)
将数据符号扩展为32位后赋给寄存器vAA
21s:指令长度32,一个寄存器,16bit立即数
例子:
-
int a = 10; -
1301 0a00 : const/16 v1, #int 10 // #a
14 31i
const vAA, #+BBBBBBBB
A:目的寄存器(8bits) B:32位常数
将数值赋给寄存器vAA
31i:指令长度48,一个寄存器,signed int,或者32位float
例子:
-
int c = 12345678; -
1403 4e61 bc00 : const v3, #float 0.000000 // #00bc614e
15 21h
const/high16 vAA, #+BBBB0000
A:目的寄存器(8bits) B: signed int(16bits)
存入16为常量到最高位寄存器,用于初始化float值
21h:指令长度32,一个寄存器,有符号的立即数(见上表说明)
例子:
-
int a = 0x40000000; -
1501 0040 : const/high16 v1, #int 1073741824 // #4000
16 21s
const-wide/16 vAA, #+BBBB
A:目的寄存器(8bits) B: signed int (16 bits)
将数值符号扩展为64位后赋给寄存器对vAA
21s:指令长度32,一个寄存器,一个常量池索引
例子:
-
long a = 1; -
1602 0100 : const-wide/16 v2, #int 1 // #1
17 31i
const-wide/32 vAA, #+BBBBBBBB
A:目的寄存器(8bits) B: signed int (32 bits)
将数值符号扩展为64位后赋给寄存器对vAA
31i:指令长度48,一个寄存器,有符号整数或float浮点数
例子:
-
long a = 12345678; -
1702 4e61 bc00 : const-wide/32 v2, #float 0.000000 // #00bc614e
18 51l
const-wide vAA, #+BBBBBBBBBBBBBBBB
A:目的寄存器(8bits) B: arbitrary double-width (64-bit) constant
存入64位常量到一对寄存器中
51l:指令长度80,一个寄存器,一个有符号整数或者64位双精度浮点数
例子:
-
long a = 12345678901234567L; -
0001d4: 1802 874b 6b5d 54dc 2b00 : const-wide v2, #double 0.000000 // #002bdc545d6b4b87
19 21h
const-wide/high16 vAA, #+BBBB000000000000
A:目的寄存器(8bits) B: signed int (16 bits)
存入16位常量到最高位的VAA寄存器中,用于初始化double long 值
21h:指令长度32,一个寄存器,一个有符号立即数,低位为0
例子:
-
long a = 0x1000000000000000L; -
1902 0010 : const-wide/high16 v2, #long 1152921504606846976 // #1000
1a 21c
const-string vAA, string@BBBB
A:目的寄存器(8bits)B: string index
将通过给定的索引获取的字符串引用移到指定的寄存器中。
21c:指令长度32,一个寄存器,一个常量池索引
例子:
-
String name="dodo"; -
1a01 0d00 : const-string v1, "dodo" // string@000d 字符串表d项
1b 31c
const-string/jumbo vAA, string@BBBBBBBB
A:目的寄存器(8bits) B: string index
将通过给定的索引获取的字符串引用移到指定的寄存器中。
31c:指令长度48,一个寄存器,一个常量池索引
例子:
这个指令出现的情况比较特殊一些,我总结了两种情况会出现这个指令
-
强制在dx编译的时候传入
--force-jumbo选项
dx --dex --output=d.dex --no-optimize --force-jumbo *.class-
String name="dodo"; -
1b01 0d00 0000 : const-string/jumbo v1, "dodo" // string@0000000d
-
-
当dex里的字符串数量很多的时候
static public final String s0 = "0";static public final String s1 = "1";......-
static public final String s32767 = "32767"; 1b01 0d00 0100 : const-string/jumbo v1, "zorch" // string@0001000d
1c 21c
const-class vAA, type@BBBB
A:目的寄存器(8bits) B: 类型索引
将通过给定的索引获取的类引用移到指定的寄存器中。如果指定的类型是原始类型,则将存储对原始类型的退化类的引用。
21c:指令长度32,一个寄存器,一个常量池索引
例子:
-
Class intClass=Integer.class; -
1c04 0300 : const-class v4, Ljava/lang/Integer; // type@0003
锁指令
1d 11x
monitor-enter vAA
A:reference-bearing register (8bit)
获得寄存器中对象的锁
1e 11x
monitor-exit vAA
A:reference-bearing register (8bit)
释放寄存器中对象的锁
11x:指令长度16,一个寄存器
注意:如果该指令需要抛出异常,则必须以 pc 已提前超出该指令的方式抛出。不妨将其想象成,该指令(在一定意义上)已成功执行,并且在该指令之后但又在下一条指令找到机会执行之前抛出异常。这种定义使得某个方法有可能将监视锁清理 catch-all(例如 finally)分块用作分块自身的监视锁清理,以便处理可能由于 Thread.stop() 的既往实现而抛出的任意异常,同时仍尽力维持适当程度的监视锁安全机制。
例子:
public static synchronized void test1(){test2();}-
public static synchronized void test2(){ -
} 1c01 0200 : const-class v1, LBlort; // type@00021d01 : monitor-enter v17100 0200 0000 : invoke-static {}, LBlort;.test2:()V // method@00021e01 : monitor-exit v10e00 : return-void0d00 : move-exception v01e01 : monitor-exit v12700 : throw v0
实例操作指令
1f 21c
check-cast vAA, type@BBBB
A: reference-bearing register (8 bits) B: type index (16 bits)
如果给定寄存器中的引用无法强制转换为指定的类型,则抛出ClassCastException。
21c:指令长度32,一个寄存器,一个常量池索引
注意:由于 A 必须始终是引用(而非原始值),因此如果 B 引用原始类型,则必然会在运行时失败(即抛出异常)。
例子:
public static Blort test(Object x) {return (Blort) x;-
} 1f01 0000 : check-cast v1, LBlort; // type@0000
20 22c
instance-of vA, vB, type@CCCC
A: destination register (4 bits)B: reference-bearing register (4 bits) C: type index (16 bits)
如果vB中的对象引用是类型ID对应类型的实例,则在vA中存储1,否则存储0,NOTE:由于B必须始终是引用(而不是基本类型),所以c中如果是基本类型,那么a中会一直是0
22c:指令长度32,两个寄存器,一个常量池索引
注意:由于 B 必须始终是引用(而非原始值),因此如果 C 引用原始类型,则始终赋值 0
例子:
-
x instanceof Blort -
2011 0000 : instance-of v1, v1, LBlort; // type@0000
21 12x
array-length vA, vB
A: destination register (4 bits) B: array reference-bearing register (4 bits)
计算vB寄存器中数组引用的元素长度并将长度存入vA中
12x:指令长度16,两个寄存器
例子:
public static void testlength(Object[] objs){int a=objs.length;-
} 2122 : array-length v2, v2
22 21c
new-instance vAA, type@BBBB
A: destination register (8 bits)B: type index
根据指定的类型构造新实例,并将对该新实例的引用存储到目标寄存器中。该类型必须引用非数组类。
21c:指令长度32,一个寄存器,一个常量池索引
例子:
-
new Object(); -
2201 0100 : new-instance v1, Ljava/lang/Object; // type@0001
数组操作指令
23 22c
new-array vA, vB, type@CCCC
A: destination register (8 bits) B: size register C: type index
根据指定的类型和大小构造新数组。该类型必须是数组类型。
22c:指令长度32,两个寄存器,一个常量池索引
例子:
int[] a= new int[4];-
Object[] b=new Object[0]; 2322 0300 : new-array v2, v2, [I // type@00032322 0400 : new-array v2, v2, [Ljava/lang/Object; // type@0004
24 35c
filled-new-array {vC, vD, vE, vF, vG}, type@BBBB
A: 数组大小和参数字数(4 位),B: 类型索引(16 位),C..G: 参数寄存器(每个寄存器各占 4 位)
根据给定类型和大小构造数组,并使用提供的内容填充该数组。该类型必须是数组类型。数组的内容必须是单字类型(即不接受 long 或 double 类型的数组,但接受引用类型的数组)。构造的实例会存储为一个“结果”,方式与方法调用指令存储其结果的方式相同,因此构造的实例必须移到后面紧跟 move-result-object 指令(如果要使用的话)的寄存器。
35c:指令长度48,5个寄存器,一个常量池索引
例子:
Object[][] a = new Object[1][13];Object[][][] b = new Object[1][14][3];Object[][][][] c = new Object[1][15][3][16];-
Object[][][][][] d = new Object[1][17][3][18][5]; 1214 :const/4 v4, #int 1 // #11225 :const/4 v5, #int 2 // #22420 0f00 5400 :filled-new-array {v4, v5}, [I // type@000f0c05 :move-result-object v56204 0500 :sget-object v4, Ljava/lang/Integer;.TYPE:Ljava/lang/Class; // field@00057120 1500 5400 :invoke-static {v4, v5}, Ljava/lang/reflect/Array;.newInstance:(Ljava/lang/Class;[I)Ljava/lang/Object; // method@00150c04 :move-result-object v41f04 1500 :check-cast v4, [[I // type@00150740 :move-object v0, v41214 :const/4 v4, #int 1 // #11225 :const/4 v5, #int 2 // #21236 :const/4 v6, #int 3 // #32430 0f00 5406 :filled-new-array {v4, v5, v6}, [I // type@000f0c05 :move-result-object v56204 0500 :sget-object v4, Ljava/lang/Integer;.TYPE:Ljava/lang/Class; // field@00057120 1500 5400 :invoke-static {v4, v5}, Ljava/lang/reflect/Array;.newInstance:(Ljava/lang/Class;[I)Ljava/lang/Object; // method@00150c04 :move-result-object v41f04 1800 :check-cast v4, [[[I // type@00180741 :move-object v1, v41214 :const/4 v4, #int 1 // #11225 :const/4 v5, #int 2 // #21236 :const/4 v6, #int 3 // #31247 :const/4 v7, #int 4 // #42440 0f00 5476 :filled-new-array {v4, v5, v6, v7}, [I // type@000f0c05 :move-result-object v56204 0500 :sget-object v4, Ljava/lang/Integer;.TYPE:Ljava/lang/Class; // field@00057120 1500 5400 :invoke-static {v4, v5}, Ljava/lang/reflect/Array;.newInstance:(Ljava/lang/Class;[I)Ljava/lang/Object; // method@00150c04 :move-result-object v41f04 1b00 :check-cast v4, [[[[I // type@001b0742 :move-object v2, v41214 :const/4 v4, #int 1 // #11225 :const/4 v5, #int 2 // #21236 :const/4 v6, #int 3 // #31247 :const/4 v7, #int 4 // #41258 :const/4 v8, #int 5 // #52458 0f00 5476 :filled-new-array {v4, v5, v6, v7, v8}, [I // type@000f0c05 :move-result-object v56204 0500 :sget-object v4, Ljava/lang/Integer;.TYPE:Ljava/lang/Class; // field@00057120 1500 5400 :invoke-static {v4, v5}, Ljava/lang/reflect/Array;.newInstance:(Ljava/lang/Class;[I)Ljava/lang/Object; // method@00150c04 :move-result-object v41f04 1e00 :check-cast v4, [[[[[I // type@001e0743 :move-object v3, v40e00 :return-void
25 3rc
filled-new-array/range {vCCCC .. vNNNN}, type@BBBB
A: 数组大小和参数字数(8 位) B: 类型索引(16 位) C: 第一个参数寄存器(16 位)N = A + C - 1
根据给定类型和大小构造数组,并使用提供的内容填充该数组。相关的说明和限制与上文所述 filled-new-array 的相同。
3rc:指令长度48,A+C-1个寄存器,一个常量池引用
N=A寄存器数量+使用的第一个寄存器-1
如下面的例子: 数组维度是6 , 第一个使用的寄存器是v4 , 那么N的值是6+4-1==9
例子:
public static void arrayTest(int a,int b,int c){Object[][][][][][] d = new Object[1][19][3][20][5][21];-
} 01a0 : move v0, v1001b1 : move v1, v1101c2 : move v2, v121214 : const/4 v4, #int 1 // #11225 : const/4 v5, #int 2 // #21236 : const/4 v6, #int 3 // #31247 : const/4 v7, #int 4 // #41258 : const/4 v8, #int 5 // #51269 : const/4 v9, #int 6 // #62506 0600 0400 : filled-new-array/range {v4, v5, v6, v7, v8, v9}, [I // type@00060c05 : move-result-object v51c04 0300 : const-class v4, Ljava/lang/Object; // type@00037120 0300 5400 : invoke-static {v4, v5}, Ljava/lang/reflect/Array;.newInstance:(Ljava/lang/Class;[I)Ljava/lang/Object; // method@00030c04 : move-result-object v41f04 0700 : check-cast v4, [[[[[[Ljava/lang/Object; // type@00070743 : move-object v3, v40e00 : return-void
26 31t
fill-array-data vAA, +BBBBBBBB (with supplemental data as specified below in “fill-array-data-payload Format”)
A: 数组引用(8 位) B: 到表格数据伪指令的有符号“分支”偏移量(32 位)
用指定的数据填充给定数组。必须引用原始类型的数组,且数据表格的类型必须与数组匹配;此外,数据表格所包含的元素个数不得超出数组中的元素个数。也就是说,数组可能比表格大;如果是这样,仅设置数组的初始元素,而忽略剩余元素。
31t:指令长度48,一个寄存器,跳转分支offset
例子:
public static int[] x={1,2,3,4,5,6,7,8,9};public static void arrayTest(){int[] a=x;-
} 1300 0900 |0000: const/16 v0, #int 9 // #92300 0300 |0002: new-array v0, v0, [I // type@00032600 0600 0000 |0004: fill-array-data v0, 0000000a // +000000066900 0000 |0007: sput-object v0, LBlort;.x:[I // field@00000e00 |0009: return-void0003 0400 0900 0000 0100 0000 0200 ... |000a: array-data (22 units)
解释一下,填充v0中的数组,在000a的位置+当前指令位置0004
异常指令
27 11x
throw vAA
A: exception-bearing register (8 bits)
抛出vAA中的异常对象
11x:指令长度16,一个寄存器
例子:
2700 :throw v0 抛出异常对象,异常对象的引用在v0寄存器
跳转指令
28 10t
goto +AA
A: signed branch offset (8 bits)
通过短偏移量无跳转跳转到目标,NOTE:跳转的偏移一定不能是0,自循环可以用goto/32或者通过在分支之前使用nop作为目标来构建
10t:指令长度16,0个寄存器,跳转、分支
注意:分支偏移量不得为 0。(自旋循环可以用 goto/32 或通过在分支之前添加 nop 作为目标来正常构造)。
例子:
28F0 : goto 0005 // -0010 跳转到当前位置-16(hex 10)的位置, 0005 是目标指令标签。
29 20t
goto/16 +AAAA
A: signed branch offset (16 bits)
同上说明
20t:指令长度32,0个寄存器,跳转
例子:
2900 0FFE : goto/16 002f // -0 无条件 1f1 跳转到当前位置-1F1H 的位置,002f 是目标指令标签。
2a 30t
goto/32 +AAAAAAAA
A: signed branch offset (32 bits)
同上
30t:指令长度48,0个寄存器,跳转
还没有复现这个指令。。。
2b 31t
packed-switch vAA, +BBBBBBBB
A: register to test B: signed “branch” offset to table data pseudo-instruction (32 bits)
实现一个switch语句,case常量是连续的指令使用索引表(table of offsets),vAA是在表中找到的具体case的指令偏移量的索引,如果无法在表中找到vAA对应的索引将继续执行下个指令(default case)
31t:指令长度48,1个寄存器,跳转
例子:
public void switchTest3(int x) {int b = 0;switch (x) {case 1:break;case 2:break;case 5:break;case 4:b = 4;break;default:b = 0;}-
} 0000: Op 0740 move-object v0, v4; */0001: Op 0151 move v1, v5; */0002: Op 1203 const/4 v3, 0; */0003: Op 0132 move v2, v3; */0004: Op 0113 move v3, v1; */0005: Op 2b03 0d00 0000 packed-switch v3, +0xd (=0x12) */0008: Op 1203 const/4 v3, 0; */0009: Op 0132 move v2, v3; */000a: Op 0e00 return-void */000b: Op 28ff goto =0xa (0xffffffff) */000c: Op 28fe goto =0xa (0xfffffffe) */000d: Op 28fd goto =0xa (0xfffffffd) */000e: Op 1243 const/4 v3, 4; */000f: Op 0132 move v2, v3; */0010: Op 28fa goto =0xa (0xfffffffa) */0x11 nop */0012: packed-switch-payload (5 units, from 1)1: 0x62: 0x73: 0x34: 0x95: 0x8
2c 31t
sparse-switch vAA, +BBBBBBBB
A: register to test B: signed “branch” offset to table data pseudo-instruction (32 bits)
实现一个switch,case常量是非连续的,这个指令使用查找表,用于标识 case常量和每个case常量的偏移量,如果vAA中无法在表中匹配将继续执行下个指令
31t:指令长度48,1个寄存器,跳转
例子:
public int switchTest2(int x) {switch (x) {case 1: {return 2;}case 10: {return 3;}case 100: {return 4;}case 1000: {return 50;}-
} return 6;-
} 0000: Op 0730 move-object v0, v3; */0001: Op 0141 move v1, v4; */0002: Op 0112 move v2, v1; */0003: Op 2c02 1300 0000 sparse-switch v2, +0x13 (=0x16) */0006: Op 1262 const/4 v2, 6; */0007: Op 0120 move v0, v2; */0008: Op 0f00 return v0; */0009: Op 1222 const/4 v2, 2; */000a: Op 0120 move v0, v2; */000b: Op 28fd goto =0x8 (0xfffffffd) */000c: Op 1232 const/4 v2, 3; */000d: Op 0120 move v0, v2; */000e: Op 28fa goto =0x8 (0xfffffffa) */000f: Op 1242 const/4 v2, 4; */0010: Op 0120 move v0, v2; */0011: Op 28f7 goto =0x8 (0xfffffff7) */0012: Op 1302 3200 const/16 v2, 0x32 */0014: Op 0120 move v0, v2; */0015: Op 28f3 goto =0x8 (0xfffffff3) */0027: sparse-switch-payload (4 units)/* 0: Key: 1 - 0x64 *//* 1: Key: 10 - 0x3e8 *//* 2: Key: 100 - 0x6 *//* 3: Key: 1000 - 0x9 */
偏移量为+0x13,说明索引表为0x03+0x13=0x16开始
这个例子和上面指令的例子不同的地方是case值是不连续的
比较指令
2d..31 23x
cmpkind vAA, vBB, vCC
A: 目标寄存器(8 位) B: 第一个源寄存器或寄存器对 C: 第二个源寄存器或寄存器对
执行指定的浮点或 long 比较;如果 b == c,则将 a 设为 0,如果 b > c,则设为 1,或者,如果 b < c,则设为 -1。浮点运算列出的“bias”表示如何处理 NaN 比较:对于 NaN 比较,“gt bias”指令返回 1,而“lt bias”指令返回 -1。 例如,建议使用 cmpg-float 来检查浮点数是否满足条件 x < y;如果结果是 -1,则表示测试为 true,其他值则表示测试为 false,原因是当前比较是有效比较但是结果不符合预期或其中一个值是 NaN。
23x:指令长度32,3个寄存器
2d: cmpl-float (lt bias) 比较vBB和vCC中的 float 值并在vAA中存入int型的返回值2e: cmpg-float (gt bias) 比较vBB和vCC中的 float 值并在vAA中存入int型的返回值2f: cmpl-double (lt bias) 比较vBB和vCC中的 double 值并在vAA中存入int型的返回值30: cmpg-double (gt bias) 比较vBB和vCC中的 double 值并在vAA中存入int型的返回值-
31: cmp-long 比较vBB和vCC中的 long 值并在vAA中存入int型的返回值 NOTE:-
setting a to 0 if b == c, 1 if b > c, or -1 if b < c -
针对浮点数比较列出的`bias`(偏差)说明NaN比较的时候是如何处理的:`gt bias`指令说明和NaN比较返回1,`lt bias`则返回-1 -
虚拟机规定浮点数比较只有有 NaN进行参与就返回false,为了维持这两种等价的源码表现一致,而且字节码尽量短: if(a < b){ if(b > a){// dosth1 //dosth1} else { } else {// dosth2 //dosth2-
} } -
具体见下面的例子 -
举例说明:如果要进行浮点数`x < y`比较,则建议使用`cmpg-float` public void foo(float a,float b){float c;if( a < b){c = a;} else {c = b;-
} if(b > a){c = a;} else {c = b;}-
} 0760 |0000: move-object v0, v60171 |0001: move v1, v70182 |0002: move v2, v80114 |0003: move v4, v10125 |0004: move v5, v22e04 0405 |0005: cmpg-float v4, v4, v53b04 0d00 |0007: if-gez v4, 0014 // +000d0114 |0009: move v4, v10143 |000a: move v3, v40124 |000b: move v4, v20115 |000c: move v5, v12d04 0405 |000d: cmpl-float v4, v4, v53d04 0800 |000f: if-lez v4, 0017 // +00080114 |0011: move v4, v10143 |0012: move v3, v40e00 |0013: return-void0124 |0014: move v4, v20143 |0015: move v3, v428f5 |0016: goto 000b // -000b0124 |0017: move v4, v20143 |0018: move v3, v428fa |0019: goto 0013 // -0006
32..37 22t
if-test vA, vB, +CCCCA: 要测试的第一个寄存器(4 位) B: 要测试的第二个寄存器(4 位) C: 有符号分支偏移量(16 位)
如果两个给定寄存器的值比较结果符合预期,则分支到给定目标寄存器。
22t:指令长度32,2个寄存器,跳转
注意:分支偏移量不得为 0。(自旋循环可以通过围绕后向 goto 进行分支或通过在分支之前添加 nop 作为目标来正常构造。)
指令说明:
A: first register to test (4 bits)B: second register to test (4 bits)-
C: signed branch offset (16 bits) 32: if-eq 如果vA==vB 跳转到目标 vA和vB是int型33: if-ne 如果vA!=vB 跳转到目标 vA和vB是int型34: if-lt 如果vA<vB 跳转到目标 vA和vB是int型35: if-ge 如果vA>=vB 跳转到目标 vA和vB是int型36: if-gt 如果vA>vB 跳转到目标 vA和vB是int型-
37: if-le 如果vA<=vB 跳转到目标 vA和vB是int型 NOTE:目标地址的偏移量不能是0 否则会发生死循环
例子:
boolean c = false;c = a == b;c = a != b;c = a < b;c = a >= b;c = a > b;-
c = a <= b; 3310 0200 : if-ne v0, v1, 0002 // +00023210 0200 : if-eq v0, v1, 0004 // +00023510 0200 : if-ge v0, v1, 0006 // +00023410 0200 : if-lt v0, v1, 0008 // +00023710 0200 : if-le v0, v1, 000a // +00023610 0200 : if-gt v0, v1, 000c // +0002
38..3d 21t
if-testz vAA, +BBBB
21t:指令长度32,一个寄存器
指令说明:
38: if-eqz 如果 vAA==0,跳转到目标 vAA是int值39: if-nez 如果 vAA!=0,跳转到目标 vAA是int值3a: if-ltz 如果 vAA<0,跳转到目标 vAA是int值3b: if-gez 如果 vAA>=0,跳转到目标 vAA是int值3c: if-gtz 如果 vAA>0,跳转到目标 vAA是int值3d: if-lez 如果 vAA<=0,跳转到目标 vAA是int值
字段操作指令
44..51 23x
arrayop vAA, vBB, vCC
A: 值寄存器或寄存器对;可以是源寄存器,也可以是目标寄存器(8 位) B: 数组寄存器(8 位) C: 索引寄存器(8 位)
在给定数组的已标识索引处执行已确定的数组运算,并将结果加载或存储到值寄存器中。
23x:指令长度32,3个寄存器
指令说明:
A: value register or pair; may be source or dest (8 bits)B: array register (8 bits)-
C: index register (8 bits) 44: aget 从int数组中获取一个int值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中45: aget-wide 从long/double数组中获取一个long/double值到vAA,vAA+1中,数组的引用位于vBB,需要获取元素的索引位于vCC中46: aget-object 从对象数组中获取一个对象引用值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中47: aget-boolean 从boolean数组中获取一个boolean值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中48: aget-byte 从byte数组中获取一个byte值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中49: aget-char 从char数组中获取一个char值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中4a: aget-short 从short数组中获取一个short值到vAA中,目的数组的引用位于vBB,需要获取元素的索引位于vCC中4b: aput 将vAA的int值存入int数组,数组引用位于vBB,元素的索引位于vCC4c: aput-wide 将vAA,vAA+1的long/double值存入long/double数组,数组引用位于vBB,元素的索引位于vCC4d: aput-object 将vAA的对象引用存入对象引用数组,数组引用位于vBB,元素的索引位于vCC4e: aput-boolean 将vAA的boolean值存入boolean数组,数组引用位于vBB,元素的索引位于vCC4f: aput-byte 将vAA的byte值存入byte数组,数组引用位于vBB,元素的索引位于vCC50: aput-char 将vAA的char值存入char数组,数组引用位于vBB,元素的索引位于vCC-
51: aput-short 将vAA的short值存入short数组,数组引用位于vBB,元素的索引位于vCC public static void testx2(){int[] a = new int[2];double[] b = new double[2];Object[] c = new Object[2];boolean[] d = new boolean[2];byte[] e = new byte[2];char[] f = new char[2];short[] g = new short[2];a[0] = 1;b[0] = 1;c[0] = new Object();d[0] = true;e[0] = 1;f[0] = 'a';-
g[0] = 1; -
} 121a : const/4 v10, #int 1 // #11226 : const/4 v6, #int 2 // #21207 : const/4 v7, #int 0 // #02360 0700 : new-array v0, v6, [I // type@00072361 0600 : new-array v1, v6, [D // type@00062362 0800 : new-array v2, v6, [Ljava/lang/Object; // type@00082363 0a00 : new-array v3, v6, [Z // type@000a2364 0400 : new-array v4, v6, [B // type@00042365 0500 : new-array v5, v6, [C // type@00052366 0900 : new-array v6, v6, [S // type@00094b0a 0007 : aput v10, v0, v71908 f03f : const-wide/high16 v8, #long 4607182418800017408 // #3ff04c08 0107 : aput-wide v8, v1, v72200 0200 : new-instance v0, Ljava/lang/Object; // type@00027010 0300 0000 : invoke-direct {v0}, Ljava/lang/Object;.<init>:()V //method@00034d00 0207 : aput-object v0, v2, v74e0a 0307 : aput-boolean v10, v3, v74f0a 0407 : aput-byte v10, v4, v71300 6100 : const/16 v0, #int 97 // #615000 0507 : aput-char v0, v5, v7510a 0607 : aput-short v10, v6, v70e00 : return-void
52..5f 22c
iinstanceop vA, vB, field@CCCC
A: 值寄存器或寄存器对;可以是源寄存器,也可以是目标寄存器(4 位) B: 对象寄存器(4 位) C: 实例字段引用索引(16 位)
对已标识的字段执行已确定的对象实例字段运算,并将结果加载或存储到值寄存器中。
22c:指令长度32,两个寄存器,常量池索引
注意:这些运算码是静态链接的合理候选项,将字段参数更改为更直接的偏移量
指令说明:
A: value register or pair; may be source or dest (4 bits)B: object register (4 bits)-
C: instance field reference index (16 bits) 52: iget 根据 字段 id 读取实例的int类型字段到 vA 中, vB 寄存器中是该实例的引用53: iget-wide 根据 字段 id 读取实例的long/double类型字段到 vA 中, vB 寄存器中是该实例的引用54: iget-object 根据 字段 id 读取实例的对象引用字段到 vA 中, vB 寄存器中是该实例的引用55: iget-boolean 根据 字段 id 读取实例的boolean类型字段到 vA 中, vB 寄存器中是该实例的引用56: iget-byte 根据 字段 id 读取实例的byte类型字段到 vA 中, vB 寄存器中是该实例的引用57: iget-char 根据 字段 id 读取实例的char类型字段到 vA 中, vB 寄存器中是该实例的引用58: iget-short 根据 字段 id 读取实例的short类型字段到 vA 中, vB 寄存器中是该实例的引用59: iput 根据 字段 id 将vA寄存器中的值存入实例的 int 型字段,vB 寄存器中是该实例的引用5a: iput-wide 根据 字段 id 将vA寄存器中的值存入实例的 long/double 型字段,vB 寄存器中是该实例的引用5b: iput-object 根据 字段 id 将vA寄存器中的值存入实例的对象引用字段,vB 寄存器中是该实例的引用5c: iput-boolean 根据 字段 id 将vA寄存器中的值存入实例的 boolean 型字段,vB 寄存器中是该实例的引用5d: iput-byte 根据 字段 id 将vA寄存器中的值存入实例的 byte 型字段,vB 寄存器中是该实例的引用5e: iput-char 根据 字段 id 将vA寄存器中的值存入实例的 char 型字段,vB 寄存器中是该实例的引用5f: iput-short 根据 字段 id 将vA寄存器中的值存入实例的 short 型字段,vB 寄存器中是该实例的引用
例子:
public class Blort{public boolean insBoolean;public byte insByte;public char insChar;public short insShort;public int insInt;public long insLong;public float insFloat;public double insDouble;-
public Object insObject; public void test2(boolean a,byte b,char c,short d,int e,long f,float g,double h,Object i) {insBoolean = a;insByte = b;insChar = c;insShort = d;insInt = e;insLong = f;insFloat = g;insDouble = h;-
insObject = i; a = insBoolean;b = insByte ;c = insChar ;d = insShort ;e = insInt ;f = insLong ;g = insFloat ;h = insDouble ;-
i = insObject ; }-
} 5c23 0000 : iput-boolean v3, v2, LBlort;.insBoolean:Z // field@00005d24 0100 : iput-byte v4, v2, LBlort;.insByte:B // field@00015e25 0200 : iput-char v5, v2, LBlort;.insChar:C // field@00025f26 0800 : iput-short v6, v2, LBlort;.insShort:S // field@00085927 0500 : iput v7, v2, LBlort;.insInt:I // field@00055a28 0600 : iput-wide v8, v2, LBlort;.insLong:J // field@0006592a 0400 : iput v10, v2, LBlort;.insFloat:F // field@00045a2b 0300 : iput-wide v11, v2, LBlort;.insDouble:D // field@0003-
5b2d 0700 : iput-object v13, v2, LBlort;.insObject:Ljava/lang/Object; // field@0007 5520 0000 : iget-boolean v0, v2, LBlort;.insBoolean:Z // field@00005620 0100 : iget-byte v0, v2, LBlort;.insByte:B // field@00015720 0200 : iget-char v0, v2, LBlort;.insChar:C // field@00025820 0800 : iget-short v0, v2, LBlort;.insShort:S // field@00085220 0500 : iget v0, v2, LBlort;.insInt:I // field@00055320 0600 : iget-wide v0, v2, LBlort;.insLong:J // field@00065220 0400 : iget v0, v2, LBlort;.insFloat:F // field@00045320 0300 : iget-wide v0, v2, LBlort;.insDouble:D // field@00035420 0700 : iget-object v0, v2, LBlort;.insObject:Ljava/lang/Object; // field@0007
60..6d 21c
sstaticop vAA, field@BBBB
A: 值寄存器或寄存器对;可以是源寄存器,也可以是目标寄存器(8 位) B: 静态字段引用索引(16 位)
对已标识的静态字段执行已确定的对象静态字段运算,并将结果加载或存储到值寄存器中。
21c:指令长度32,一个寄存器,常量池索引
注意:这些运算码是静态链接的合理候选项,将字段参数更改为更直接的偏移量。
指令说明:
60: sget 根据字段ID读取静态int字段到vAA中61: sget-wide 根据字段ID读取静态long/double字段到vAA,vAA+1中62: sget-object 根据字段ID读取静态静态对象引用字段到vAA中63: sget-boolean根据字段ID读取静态boolean字段到vAA中64: sget-byte 根据字段ID读取静态byte字段到vAA中65: sget-char 根据字段ID读取静态char字段到vAA中66: sget-short 根据字段ID读取静态short字段到vAA中67: sput 根据字段ID将vAA寄存器中的值赋值到int型静态字段中68: sput-wide 根据字段ID将vAA,vAA+1寄存器中的long/double值赋值到long/double型静态字段中69: sput-object 根据字段ID将vAA寄存器中的对象引用赋值到对象引用型静态字段中6a: sput-boolean根据字段ID将vAA寄存器中的boolean值赋值到boolean型静态字段中6b: sput-byte 根据字段ID将vAA寄存器中的byte值赋值到byte型静态字段中6c: sput-char 根据字段ID将vAA寄存器中的char值赋值到char型静态字段中6d: sput-short 根据字段ID将vAA寄存器中的short值赋值到short型静态字段中
例子:
public static boolean staticBoolean;public static byte staticByte;public static char staticChar;public static short staticShort;public static int staticInt;public static long staticLong;public static float staticFloat;public static double staticDouble;-
public static Object staticObject; public static void test2(boolean a,byte b,char c,short d,int e,long f,float g,double h,Object i) {staticBoolean = a;staticByte = b;staticChar = c;staticShort = d;staticInt = e;staticLong = f;staticFloat = g;staticDouble = h;-
staticObject = i; a = staticBoolean;b = staticByte ;c = staticChar ;d = staticShort ;e = staticInt ;f = staticLong ;g = staticFloat ;h = staticDouble ;i = staticObject ;-
} 6a02 0000 : sput-boolean v2, LBlort;.staticBoolean:Z // field@00006b03 0100 : sput-byte v3, LBlort;.staticByte:B // field@00016c04 0200 : sput-char v4, LBlort;.staticChar:C // field@00026d05 0800 : sput-short v5, LBlort;.staticShort:S // field@00086706 0500 : sput v6, LBlort;.staticInt:I // field@00056807 0600 : sput-wide v7, LBlort;.staticLong:J // field@00066709 0400 : sput v9, LBlort;.staticFloat:F // field@0004680a 0300 : sput-wide v10, LBlort;.staticDouble:D // field@0003690c 0700 : sput-object v12, LBlort;.staticObject:Ljava/lang/Object; // field@00076300 0000 : sget-boolean v0, LBlort;.staticBoolean:Z // field@00006400 0100 : sget-byte v0, LBlort;.staticByte:B // field@00016500 0200 : sget-char v0, LBlort;.staticChar:C // field@00026600 0800 : sget-short v0, LBlort;.staticShort:S // field@00086000 0500 : sget v0, LBlort;.staticInt:I // field@00056100 0600 : sget-wide v0, LBlort;.staticLong:J // field@00066000 0400 : sget v0, LBlort;.staticFloat:F // field@00046100 0300 : sget-wide v0, LBlort;.staticDouble:D // field@00036200 0700 : sget-object v0, LBlort;.staticObject:Ljava/lang/Object; // field@0007
方法调用指令
6e..72 35c
invoke-kind {vC, vD, vE, vF, vG}, meth@BBBB
A: 参数字数(4 位) B: 方法引用索引(16 位) C..G: 参数寄存器(每个寄存器各占 4 位)
调用指定的方法。所得结果(如果有的话)可能与紧跟其后的相应 move-result* 变体指令一起存储。使用 invoke-virtual 调用正常的虚方法(该方法不是 private、static 或 final,也不是构造函数)。 当 method_id 引用非接口类方法时,使用 invoke-super 调用最近超类的虚方法(这与调用类中具有相同 method_id 的方法相反)。invoke-virtual 具有相同的方法限制。 在版本 037 或更高版本的 Dex 文件中,如果 method_id 引用接口方法,则使用 invoke-super 来调用在该接口上定义的该方法的最具体、未被覆盖版本。invoke-virtual 具有相同的方法限制。在版本 037 之前的 Dex 文件中,具有接口 method_id 是不当且未定义的。 invoke-direct 用于调用非 static 直接方法(也就是说,本质上不可覆盖的实例方法,即 private 实例方法或构造函数)。invoke-static 用于调用 static 方法(该方法始终被视为直接方法)。invoke-interface 用于调用 interface 方法,也就是说,在具体类未知的对象上,使用引用 interface 的 method_id。
35c:指令长度48,5个寄存器,常量池索引
指令说明:
A: argument word count (4 bits)B: method reference index (16 bits)-
C..G: argument registers (4 bits each) -
调用指定的方法,生成的结果(如果有的话)可以用合适的`move-result*`来移动结果到其他寄存器中给后续使用 6e: invoke-virtual 用于调用一个普通的虚方法(一个不是private,static或final的方法,也不是构造函数)6f: invoke-super 调用带参数的直接父类的虚方法70: invoke-direct 直接调用带参数的方法71: invoke-static 调用带参数的静态方法-
72: invoke-interface 调用带参数的接口方法 当method_id引用非接口类的方法时invoke-super用于调用最接近的超类的虚方法(而不是调用类中具有相同method_id的方法),invoke-virtual 具有相同的限制。-
在Dex文件版本037或更高版本中,如果method_id引用接口方法,则使用invoke-super调用该接口上定义的该方法的最特定的non-overridden版本,在037版本之前的版本中,method_id指向接口的方法是非法的。 invoke-direct用于调用non-static方法(即,其本质是non-overrideable的实例方法,即private实例方法或构造函数)。invoke-static用于调用静态方法invoke-interface用于调用 interface 方法,即在不知道当前对象的具体类上,使用引用接口的method_id
例子:
interface TestInterface{void iM();}public class TestMethod implements TestInterface{-
public void m1(int a,int b,int c,int d){ -
} -
public static void m2(){ -
} @Override-
public void iM(){ }-
} -
class TestMethod2{ -
private void m3(){} public void callMethod(){TestMethod testObject=new TestMethod();testObject.m1(1,2,3,4);m3();TestMethod.m2();TestInterface in=new TestMethod();in.iM();-
super.toString(); }-
} 2200 0300 : new-instance v0, LTestMethod; // type@00037010 0400 0000 : invoke-direct {v0}, LTestMethod;.<init>:()V // method@00041211 : const/4 v1, #int 1 // #11222 : const/4 v2, #int 2 // #21233 : const/4 v3, #int 3 // #31244 : const/4 v4, #int 4 // #46e54 0600 1032 : invoke-virtual {v0, v1, v2, v3, v4}, LTestMethod;.m1:(IIII)V // method@00067010 0300 0500 : invoke-direct {v5}, LTestMethod2;.m3:()V // method@00037100 0700 0000 : invoke-static {}, LTestMethod;.m2:()V // method@00072200 0300 : new-instance v0, LTestMethod; // type@00037010 0400 0000 : invoke-direct {v0}, LTestMethod;.<init>:()V // method@00047210 0000 0000 : invoke-interface {v0}, LTestInterface;.iM:()V // method@00006f10 0900 0500 : invoke-super {v5}, Ljava/lang/Object;.toString:()Ljava/lang/String; // method@00090e00 : return-void
说明: 调用 TestMethod 的 m1 方法,该指令共有 4 个参数(操作码第二个字节的 4 个最高有效位 5) 。参数 v0 是”this”实例,v1, v2, v3, v4 是 m1 方法的参数,(IIII)V 的 4 个 I 分表表示 4 个 int 型 参数,V 表示返回值为 void。
74..78 3rc
invoke-kind/range {vCCCC .. vNNNN}, meth@BBBB
3rc:指令长度48,指令长度不定,常量池索引
指令说明:
A: argument word count (8 bits)B: method reference index (16 bits)C: first argument register (16 bits)-
N = A + C - 1 74: invoke-virtual/range75: invoke-super/range76: invoke-direct/range77: invoke-static/range-
78: invoke-interface/range public void test(){int i1 = 0;.......-
int i13 = 0; blort(0);blort2(0);-
} public void blort(long x) {// blank}-
public void blort2(int x){ -
} 7403 0100 0f00 : invoke-virtual/range {v15, v16, v17}, LBlort;.blort:(J)V // method@00017402 0200 0f00 : invoke-virtual/range {v15, v16}, LBlort;.blort2:(I)V // method@0002
说明:上述方法中 v15 指的是 this ,由 blort 方法参数是 long ,所以使用的寄存器是两个,而 blort 方法参数类型是 int ,所以只需要一个寄存器就可以
数据转换
7b..8f 12x
unop vA, vB
A: 目标寄存器或寄存器对(4 位) B: 源寄存器或寄存器对(4 位)
对源寄存器执行已确定的一元运算,并将结果存储到目标寄存器中。
12x:指令长度16,两个寄存器
指令说明:
A: destination register or pair (4 bits)-
B: source register or pair (4 bits) 7b: neg-int 计算 vA=-vB 并将结果存入vA7c: not-int7d: neg-long 计算vA,vA+1=-(vB,vB+1) 并将结果存入vA,vA+17e: not-long7f: neg-float 计算 vA=-vB 并将结果存入vA80: neg-double 计算vA,vA+1=-(vB,vB+1) 并将结果存入vA,vA+181: int-to-long 计算vA,vA+1=-(vB,vB+1) 并将结果存入vA,vA+182: int-to-float 转换vB寄存器中的int值转为long型存入vA,vA+183: int-to-double 转换vB寄存器中的int值转为double型存入vA,vA+184: long-to-int 转换vB,vB+1寄存器中的long型值为int型值存入vA中85: long-to-float 转换vB,vB+1寄存器中的long型值为float型值存入vA中86: long-to-double 转换vB,vB+1寄存器中的long型值为double型值存入vA,vA+1中87: float-to-int 转换vB寄存器中的float值为int型值存入vA88: float-to-long 转换vB寄存器中的float值为long型值存入vA,vA+189: float-to-double 转换vB寄存器中的float值为double型值存入vA,vA+18a: double-to-int 转换vB,vB+1寄存器中的double型值为int型值存入vA8b: double-to-long 转换vB,vB+1寄存器中的double型值为long型值存入vA,vA+18c: double-to-float 转换vB,vB+1寄存器中的double型值为float型值存入vA8d: int-to-byte 转换vB寄存器中的int值为byte型值存入vA8e: int-to-char 转换vB寄存器中的int值为char型值存入vA-
8f: int-to-short 转换vB寄存器中的int值为short型值存入vA int a = 1;int b = -a;float c = 1f;float d = -c;long e = 1l;long f = -e;double g = 1.0;double h = -g;e = a;c = a;-
g = a; a = (int)c;e = (long)c;-
g = c; a = (int)e;c = (float)e;-
g = (double)e; a = (int)g;c = (float)g;-
e = (long)g; 1210 : const/4 v0, #int 1 // #17b01 : neg-int v1, v01501 803f : const/high16 v1, #int 1065353216 // #3f807f11 : neg-float v1, v11602 0100 : const-wide/16 v2, #int 1 // #17d22 : neg-long v2, v21902 f03f : const-wide/high16 v2, #long 4607182418800017408 // #3ff08022 : neg-double v2, v28102 : int-to-long v2, v08201 : int-to-float v1, v08302 : int-to-double v2, v08710 : float-to-int v0, v18812 : float-to-long v2, v18910 : float-to-double v0, v18420 : long-to-int v0, v28520 : long-to-float v0, v28620 : long-to-double v0, v28a02 : double-to-int v2, v08c02 : double-to-float v2, v08b00 : double-to-long v0, v00e00 : return-void
数据运算
90..af 23x
binop vAA, vBB, vCC
A: 目标寄存器或寄存器对(8 位) B: 第一个源寄存器或寄存器对(8 位) C: 第二个源寄存器或寄存器对(8 位)
对两个源寄存器执行已确定的二元运算,并将结果存储到目标寄存器中。
23x:指令长度32,3个寄存器
指令说明:
A: destination and first source register or pair (4 bits)-
B: second source register or pair (4 bits) 90: add-int91: sub-int92: mul-int93: div-int94: rem-int95: and-int96: or-int97: xor-int98: shl-int99: shr-int9a: ushr-int9b: add-long9c: sub-long9d: mul-long9e: div-long9f: rem-longa0: and-longa1: or-longa2: xor-longa3: shl-longa4: shr-longa5: ushr-longa6: add-floata7: sub-floata8: mul-floata9: div-floataa: rem-floatab: add-doubleac: sub-doublead: mul-doubleae: div-doubleaf: rem-double
d0..d7 22s
binop/lit16 vA, vB, #+CCCC
A: 目标寄存器(4 位) B: 源寄存器(4 位) C: 有符号整数常量(16 位)
对指定的寄存器(第一个参数)和字面值(第二个参数)执行指定的二元运算,并将结果存储到目标寄存器中。
22s:指令长度32,两个寄存器,短整型立即数
指令说明:
A: destination register (4 bits)B: source register (4 bits)-
C: signed int constant (16 bits) d0: add-int/lit16 计算 vB + lit16 并将结 果存入 vA。d1: rsub-int (reverse subtract) 计算 vB - lit16 并将结 果存入 vA。d2: mul-int/lit16 计算 vB * lit16 并将结 果存入 vA。d3: div-int/lit16 计算 vB / lit16 并将结 果存入 vA。d4: rem-int/lit16 计算 vB % lit16 并将结 果存入 vA。d5: and-int/lit16 计算 vB 与 lit16 并将结 果存入 vA。d6: or-int/lit16 计算 vB 或 lit16 并将结 果存入 vA。d7: xor-int/lit16 计算 vB 异或 lit16 并将 结果存入 vA。
d8..e2 22b
binop/lit8 vAA, vBB, #+CC
A: 目标寄存器(8 位) B: 源寄存器(8 位) C: 有符号整数常量(8 位)
对指定的寄存器(第一个参数)和字面值(第二个参数)执行指定的二元运算,并将结果存储到目标寄存器中。
22b:指令长度32,两个寄存器,8位有符号立即数
指令说明:
A: destination register (8 bits)B: source register (8 bits)-
C: signed int constant (8 bits) d8: add-int/lit8 计算 vBB + lit8 并将结果存入 vAA。d9: rsub-int/lit8 计算 vBB - lit8 并将结果存入 vAA。da: mul-int/lit8 计算 vBB * lit8 并将结果存入 vAA。db: div-int/lit8 计算 vBB / lit8 并将结果存入 vAA。dc: rem-int/lit8 计算 vBB % lit8 并将结果存入 vAA。dd: and-int/lit8 计算 vBB 与 lit8 并将结果存入 vAA。de: or-int/lit8 计算 vBB 或 lit8 并将结果存入 vAA。df: xor-int/lit8 计算 vBB 异或 lit8 并将结果存入 vAA。e0: shl-int/lit8 左移 vBB,lit8 指定移动的位置,并将结果存入 vAA。e1: shr-int/lit8 右移 vBB,lit8 指定移动的位置,并将结果存入 vAA。e2: ushr-int/lit8 无符号右移 vBB,lit8 指定移动的位置,并将结果存入VAA。
Insruction Transformer
有了上面的知识,我们看下面的逻辑就相对简单一些了,我们上上章说到我们拿到的Code是不能直接进行对比的,所以Tinker写了一个InstructionTransformer来对字节码进行一个转换操作,来解决上述的问题
public short[] transform(short[] encodedInstructions) throws DexException {ShortArrayCodeOutput out = new ShortArrayCodeOutput(encodedInstructions.length);//因为每个指令的长度是u1 也就是0~255InstructionPromoter ipmo = new InstructionPromoter();//地址转换,应对类似const-string 到const-string/jumbo的地址扩展情况InstructionWriter iw = new InstructionWriter(out, ipmo);-
InstructionReader ir = new InstructionReader(new ShortArrayCodeInput(encodedInstructions)); try {// First visit, we collect mappings from original target address to promoted target address.-
ir.accept(new InstructionTransformVisitor(ipmo)); // Then do the real transformation work.ir.accept(new InstructionTransformVisitor(iw));} catch (EOFException e) {throw new DexException(e);-
} return out.getArray();}
InstructionReader用来解析 Code 里了bytecode信息,提取索引等相关内容。
下面直接进入InstructionReader类来看一下Tinker是如何解析字节码的
从前面的内容可知,一段指令规定了长度和寄存器使用个数和后面附加的一些内容。所以我们可以根据指令里的操作码来判断每个指令的布局,从而按照格式读取出相应的内容。
下面以第一章中的代码来举例说明:
public void test(int c){int a=c;}
那么我们从dex中读取的字节码内容如下:
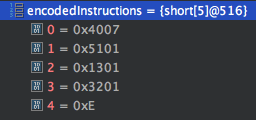
对应Tinker中的源码来解析一下这个过程:
-
//InstructionReader.java int currentAddress = codeIn.cursor();//取出当前cursor,从0开始 //①int opcodeUnit = codeIn.read();//读取每个指令码 //②int opcodeForSwitch = Opcodes.extractOpcodeFromUnit(opcodeUnit);//读取低位操作码// ③
① 部分是按照字节码顺序读取字节码,每个方法开始的位置都是0
② 从字节码数组中取出指令,我们这里拿到的是 0x4007
③ 前面可知从dex中的 EndianTag 中可知dex是小端存储的,也就是说如果真实值是 0x12345678 那么在文件中存储为 0x78563412。所以我们取出来的指令其实按照描述方应该是 0x0740。 从 bytecode 章可知 07 对应的指令是 move-object vA, vB,指令长度16,使用两个寄存器

两个寄存器一个是v0,一个是v4,那么这段指令可以转换为 move-object v0,v4
从上文和官网的 instruction-formats 文档可知,寄存器的使用有如下情况:
-
//没有使用寄存器 public void visitZeroRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal)//使用一个寄存器-
public void visitOneRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a) //使用两个寄存器 比如:move vA,vB-
public void visitTwoRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a, int b) //使用三个寄存器 比如:cmpkind vAA,vBB,vCC-
public void visitThreeRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a, int b, int c) //使用四个寄存器 比如像 invoke-kind {vC, vD, vE, vF, vG} 这样寄存器不固定的情况-
public void visitFourRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a, int b, int c, int d) //使用五个寄存器 比如像 invoke-kind {vC, vD, vE, vF, vG} 这样寄存器不固定的情况-
public void visitFiveRegisterInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a, int b, int c, int d, int e) //这种情况下寄存器的数量是计算出来的,比如 invoke-kind/range {vCCCC .. vNNNN}, meth@BBBB 系列-
public void visitRegisterRangeInsn(int currentAddress, int opcode, int index, int indexType, int target, long literal, int a, int registerCount) // 适用于读取case常量非连续的查找表用-
public void visitSparseSwitchPayloadInsn(int currentAddress, int opcode, int[] keys, int[] targets) // 适用于读取连续的case常量索引表用public void visitPackedSwitchPayloadInsn(int currentAddress, int opcode, int firstKey, int[] targets)-
} //适用于读取用静态数据填充数组时的情况public void visitFillArrayDataPayloadInsn(int currentAddress, int opcode, Object data, int size, int elementWidth)
ok,有了上面的内容我们来看一下transform方法是如何应对第一章中方法没有修改但是字节码变化的问题。
由于dex生成的时候收到多个方面的原因会造成我们并没有修改一个方法但是这个方法的字节码产生了变化,Tinker针对这些情况做出了不同的处理,下面分情况讨论:
注:我们的旧版本代码不会产生变化,所以这里提前写出旧版本的例子代码
旧版本
000144: 6200 0000 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@0000000148: 1a01 0a00 |0002: const-string v1, "hello dodola5" // string@000a00014c: 6e20 0200 1000 |0004: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@0002000152: 0e00 |0007: return-void
情况1
旧版本dex中一个方法没有修改但是新版本dex中这个对应的方法字节码产生变化了
新版本
6200 0500 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@00051a01 1400 |0002: const-string v1, "hello dodola5" // string@00146e20 0200 1000 |0004: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00020e00 |0007: return-void
这里只分析一下InstructionWriter过程,这个过程其实是一个old instruction->new instruction的过程。
首先也会进入到InstructionReader的读取字节码的方法中accept,假设这里读取到address==0002的地方:

下一步我们就将对应新dex里的mapping取出来了 000a>0014

进入InstructionWriter.visitOneRegisterInsn过程中,
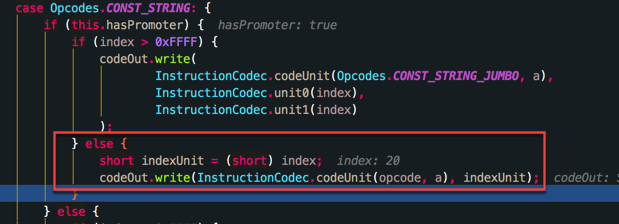
注意 上面标红框的地方,我们写入到out字节码中的字符串 index 是0014,这里把旧的 Code 字节码强行改变,所以在做对比的时候这两个的字节码是完全一样的,这个方法也不会将该方法打入补丁包中,这个过程对补丁包的大小影响很大,能减少好多原本没有改变的方法打入补丁包中。
情况2
旧版本没有使用force-jumbo而新版本使用了force-jumbo的情况
注意:新的dex强制使用了force-jumbo来编译用来演示另一个坑dx --dex --output=new.dex --force-jumbo Foo.class
新版本
6200 0500 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@00051b01 1400 0000 |0002: const-string/jumbo v1, "hello dodola5" // string@000000146e20 0200 1000 |0005: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00020e00 |0008: return-void
我们直接看读取到第二行变化的位置:
然后代码进入到InstructionTransformVisitor的流程中

从第一章的 diff 算法的分析中我们得到了如下的对象表,并在这里需要在旧的stringsIdsMap中找到旧 id -> 新 id 的映射,也就是上面代码中000a到0000 0014的变化
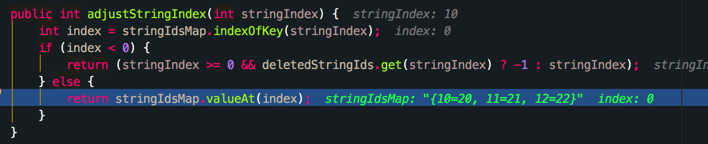
然后进入到InstructionPromoter流程中

由于我们对应到新的 dex 中的值是0000 0014 操作码是const-string,由于我们取出的值并没有超过0xFFFF,所以Tinker并没有处理这种情况而是直接按照0014的情况处理,因为我们没有办法判断用户开启了jumbo编译并且字符串没有超过限制的情况。
后续也没有什么特殊的,Tinker 把这种情况当成修改了方法代码的情况,也就是认为我们手动修改了该方法,这个方法最终会打入补丁包中,所以我们应该避免旧的dex没有开启jumbo编译而新的dex中 String ID没有超过 0xFFFF 的数量并且强制开启了jumbo编译的情况。。
因为这种情况下会造成补丁包变得很大,tinker会把这个我们本来没有修改过的方法打入补丁包中.下面是生成补丁包的内容:
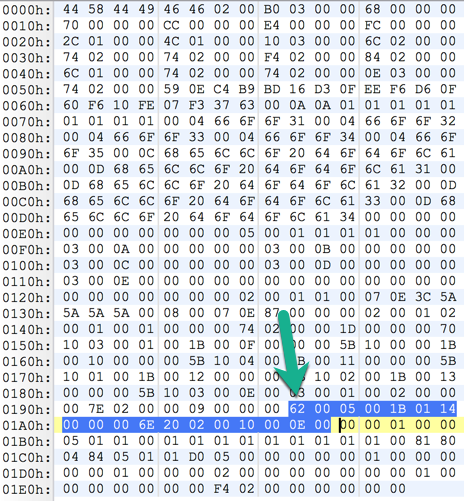
情况3
新dex中由于新增的字符串数超过0xFFFF数导致dx工具强制使用jumbo模式编译,这次为了构造这种情况,需要写一个新的旧版本dex
旧版本
6200 0000 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@00001a01 0c00 |0002: const-string v1, "zzzzzzz" // string@000c6e20 0200 1000 |0004: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00020e00 |0007: return-void
新版本
6200 0080 |0000: sget-object v0, Ljava/lang/System;.out:Ljava/io/PrintStream; // field@80001b01 1000 0100 |0002: const-string/jumbo v1, "zzzzzzz" // string@000100106e20 0400 1000 |0005: invoke-virtual {v0, v1}, Ljava/io/PrintStream;.println:(Ljava/lang/String;)V // method@00040e00 |0008: return-void
上述内容有两处变化一个是取字符串的指令从1A变成了1B,000c变成了00010010
首先和上面一样进入InstructionReader逻辑

然后从旧的dex中获取新id的对应id

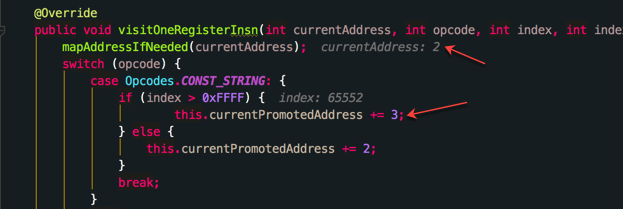
从上图中我们可以看到取出的id是65552也就是上面代码中对应的00010010
然后进入InstructionPromoter流程中
此处需要特别注意一下:
因为我们旧字节码在这个地方是1a01 0c00指令长度32,而新的字节码是1b01 1000 0100指令长度48,当我们读取到这的时候currentPromotedAddress+=3,其实下一次读取的时候我们读取old的位置是currentAddress=4,而对应新的address是5,所以我们为了在旧dex输出的时候腾出一个16长度的位置要做一个address的对应表,保证生成的字节码是正确的:

ok,Read的过程完了,我们进入Write的过程,省略读取字节码的部分,直接进入到write部分的代码
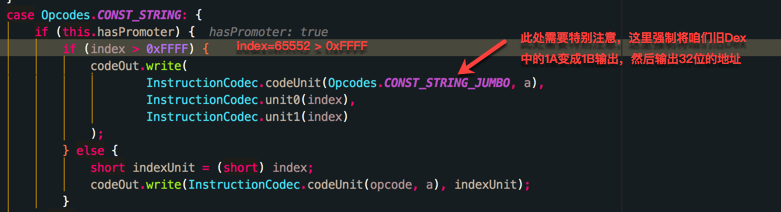
总结
从上面的几种情况看,Transformer能保证一部分情况下减小补丁大小的体积,但更多情况下我们还需要自己去避免这种情况,比如我们在基础包发布的时候就强制开启jumbo的编译这样的情况就会好很多。
结尾
哇咔咔,整个 Transformer 的流程就分析完了,最后的例子处我只写了const-string到const-string/jumbo的转换,其实从源码中分析还有goto->goto/16,goto/32的情况,但是这种情况复现比较困难,原理和 const-string->const-string/jumbo的情况一致,所以也不过多的叙述了。
最后感谢微信小唐(tomystang)和Lody给的指导。
后续的坑:
1. ART下机器码那块的地址偏移情况分析
2. Tinker Loader,这部分大家问得问题最多
3. Tinker Resource Diff & Load
参考资料
- https://source.android.com/devices/tech/dalvik/dalvik-bytecode.html
- Smali 学习笔记
- 丰生强.Android 软件安全与逆向分析.2013-02-01